
#2 - Let's build a production-ready ML product
Join me in building it on a shoestring budget - anywhere between free and cheap! 🤣🏎️

Hi friends,
Choosing the right project to work on can be as tricky as finding your way through a maze of endless options.
New AI announcements (especially Gen AI) seem to drop like clockwork these days, and the unlimited project choices can be overwhelming and paralyzing. If you know me, you'll know I'm a big fan of Formula 1. So, it wasn't hard when it came to picking my next machine learning project. I needed something that would be exciting to myself, a project I could pour endless hours into without blinking an eye.

Friends, we're about to dive into the exciting world of Formula 1 race prediction!
This isn't my first rodeo with race prediction: I dipped my toes into it during a Data Science boot camp I completed a while back. That experience taught me the ropes of ML model development, however, this time, it will be a full-on ML-based product. Buckle up as we delve into applied data science!
To start off, here are our requirements and constraints:
serves race predictions using a production-ready (infinitely scaleable) architecture
web application deployed on a modern stack
historical data comes from an API, and miscellaneous race information will be scraped from online source/s
using the FTI Pipeline Architecture as described here, we will have a feature pipeline that will be run on a specified schedule, to update racing data when they become available.
data validation and integrity checks are part of our feature pipeline.
a training pipeline that will be run when new features become available. As this series is not intended as a tutorial in model development, we will be using a good model (deep learning or an ML model, well, I have not made up my mind yet), we will discuss model selection criteria as we progress further.
use a modern platform to track our training, model tuning, and models created by this pipeline
a batch inference pipeline, that runs when a new model is ready and populates a database (or simply a file in storage) with pre-calculated predictions
a race prediction API that returns these pre-calculated prediction results to our user interface
our system will also have model prediction performance monitoring built-in
use exclusively free* and serverless infrastructure.
*note: A generous free tier is more than enough for our use case.
Tech Stack
Looking at the tech stack dump below, it seems a lot, and it is, however, this is what you would typically find with the industry or with startups building MVPs. When you are building a product, you’ll find yourself cobbling different applications together, as there’s no ONE application that can do it all.

Don’t worry, we will go through each one as we use them in the project. Here are some descriptions of each tool:
Python - the bulk of this project will be written in Python, as it is easy to learn and maintain, and it’s such a rich ecosystem that it is the de-facto standard in machine learning.
Metaflow - all our Python workflows will be orchestrated by Metaflow, an open-source ML tool built and battle-tested in Netflix. I’ve been using it for a while now, and just love how I can easily transition from my laptop to the cloud with very minimal changes.
NextJS on Vercel - ReactJS is great, but NextJS is even better. It is a superset of React and is designed for production as it is super fast. I wrote a blog article about it a while back, and it was already awesome then.
Beautiful Soup - Most of the dataset for the project comes from Ergast.com, however, we are on borrowed time as it has been deprecated, and will be available only up to the end of 2024. For the latest race results, we will be scraping it straight from the Formula 1 website.
Hopsworks - I have mentioned that we will be using the FTI pipeline architecture, the mental model from the Hopswroks team. This architecture revolves around the use of feature stores, and we will use them here.
DuckDB - we will be using DuckDB instead of Pandas to work with our data in SQL more easily. I will always take the chance to not have to use Pandas if I can help it.
AWS Lambda - since our model serving is quite simple, where we’re only really serving online predictions from our cached and pre-calculated results, we don’t need to go through the complexities of using something like Seldon, for leveraging Kubernetes clusters.
Comet - for experiment tracking and model registry, we can use trusty Comet, with its easy-to-use UI and Python API.
Great Expectations - to enforce data validations and ensure data quality as the data is ingested into our pipeline, we use GX.
Evidently AI - monitoring the models in production is made possible by Evidently AI, and it can be used to detect drift and help us decide whether to retrain our models or not.
I’d like to think that our budget for this project - is anywhere between free and cheap! 🤣
- JO
Architecture Diagram
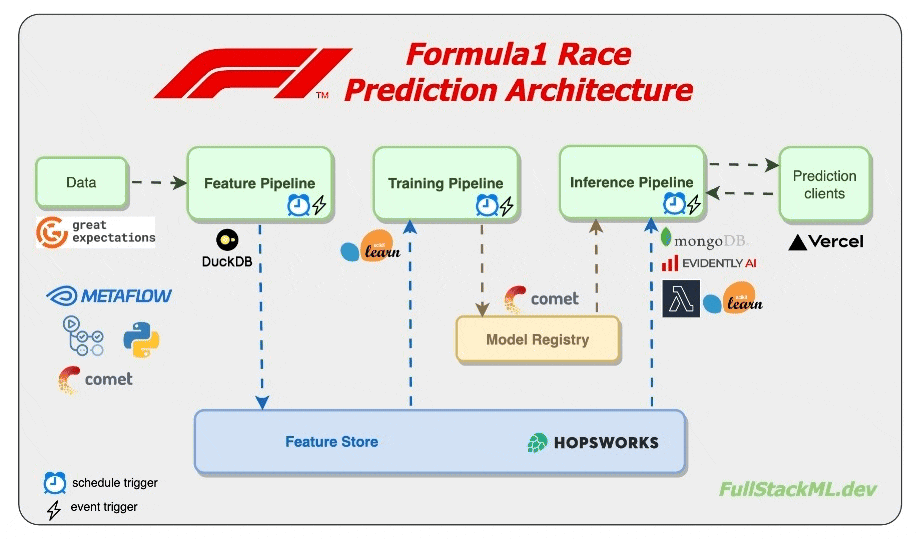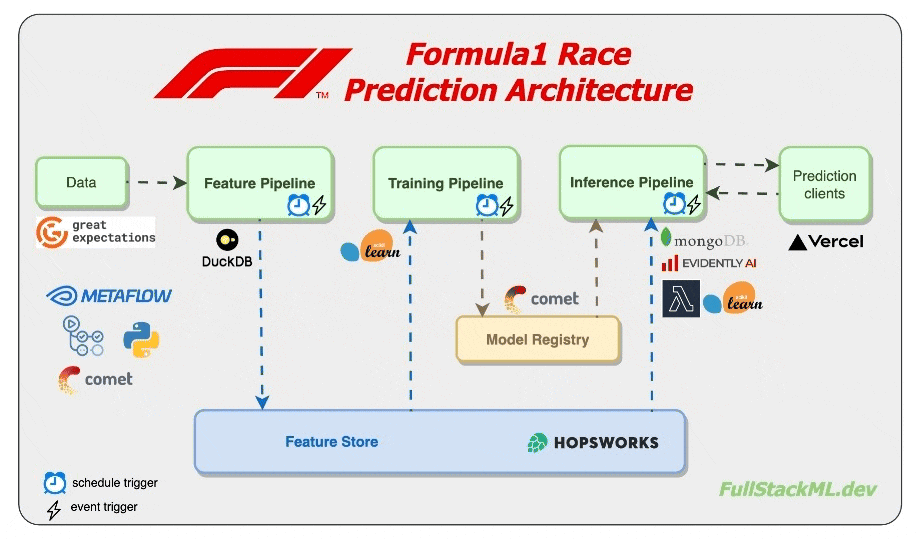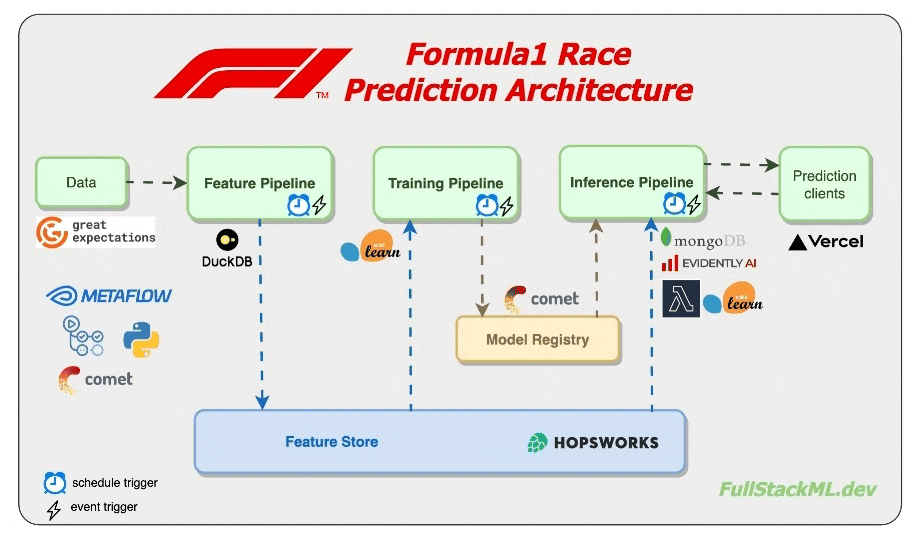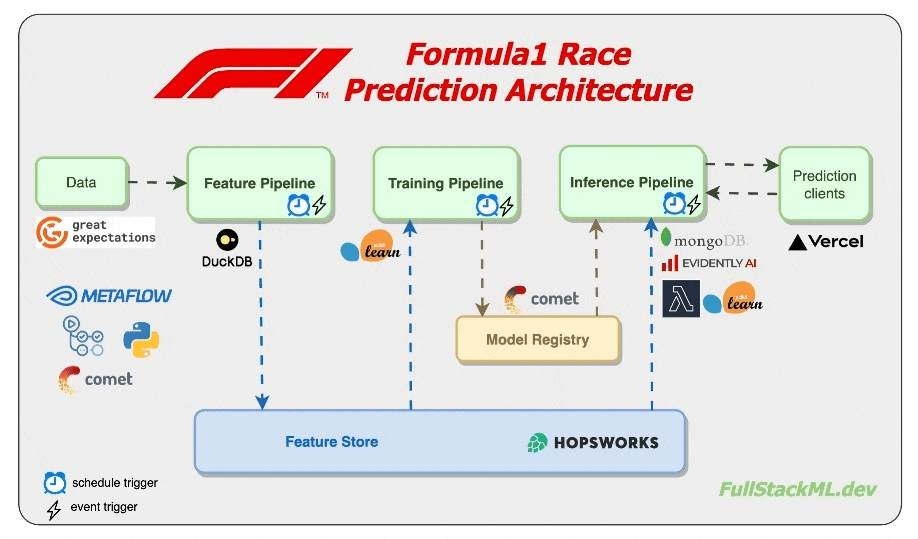
We now have the architecture diagram above, which we will use as a guide as we build this project. We might add changes here and there, but the main takeaway here is that instead of a single ‘end-to-end‘ pipeline, a production-ready machine learning system is a modular, easily maintainable, and scalable system. I’ve marked the ML tooling we plan to use to give a better idea of our end goal.
I think that should be about it for now. In the next edition, we will start building our workflows.
Till then,
JO