
#1 - Building machine learning systems is hard
But it doesn't have to be that way...

Hi friends,
Building machine learning systems is hard.
Software development is a complex process, where development teams have to juggle creativity, customer requirements, technology, and many delivery-related issues. Furthermore, in the last few years, more and more products have incorporated machine learning, making what was already a complex undertaking even more challenging.
In one of my first articles on machine learning, I used the following image to describe a machine learning product (copyright Google), showing all its components, and how model development plays a very minor role. How can one build a product given the image below?
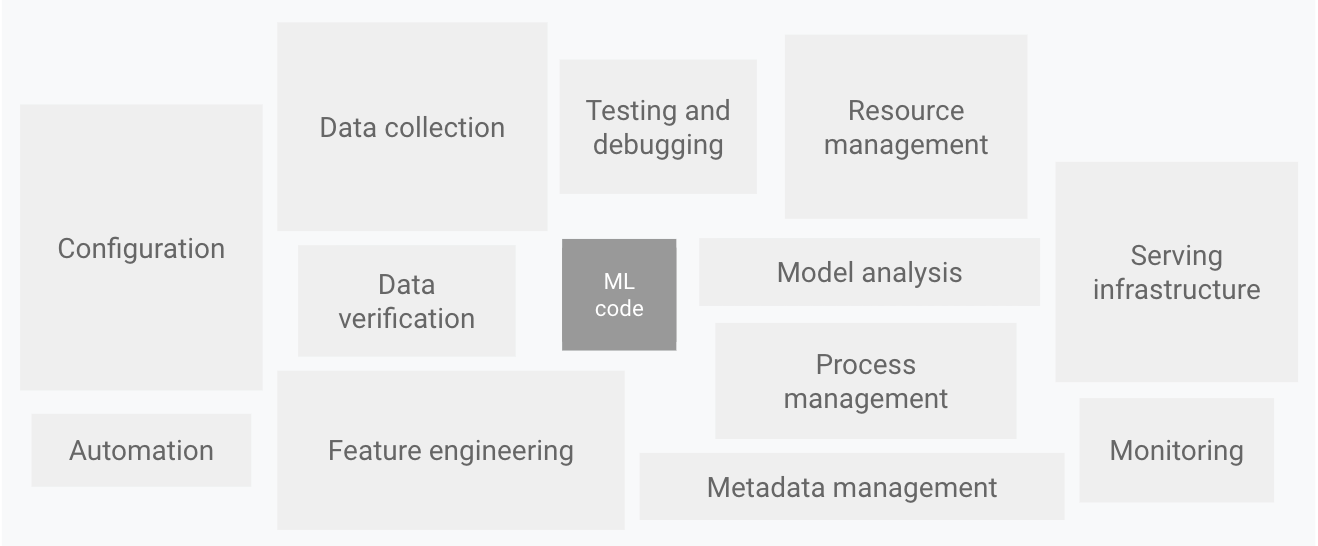
In the last couple of years, more and more tools have been added to the MLOps ecosystem. Why is it then that a recent Gartner survey revealed that on average only 54% of AI projects make it from pilot to production? Just one per cent up from the previous year, with all this tooling at our disposal, surely we’re missing something. Yes, many of our models just don’t make it to production.
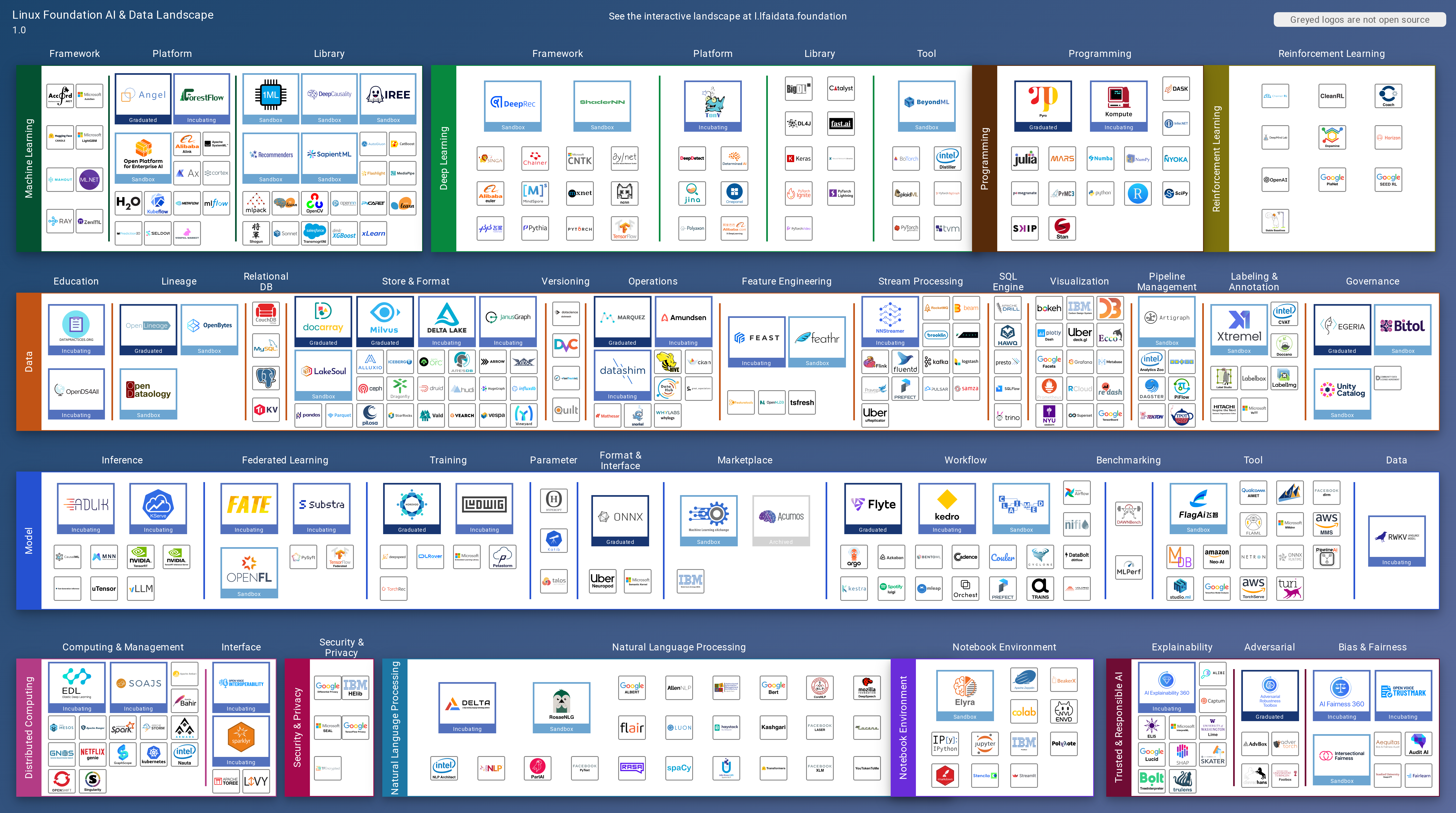
One would think that we’d have this figured out by now. Couldn’t be anymore further from the truth. As described here and here, it seems that more tool choices do not translate to increased success in productionizing ML systems.
So what are we to do then?
Getting over software complexity
Coming from a software engineering background, I'm no stranger to the complexities of software development. To address this, the industry employs various strategies, and one notable approach is the use of architectural frameworks. For instance, the Model-View-Controller (MVC) framework gained popularity in the .NET ecosystem around 2010, as it facilitated web developers in creating web applications with a modular and shared understanding of web application development. (As an aside, it’s not something you would want to use anymore these days as there have been many advancements since then)
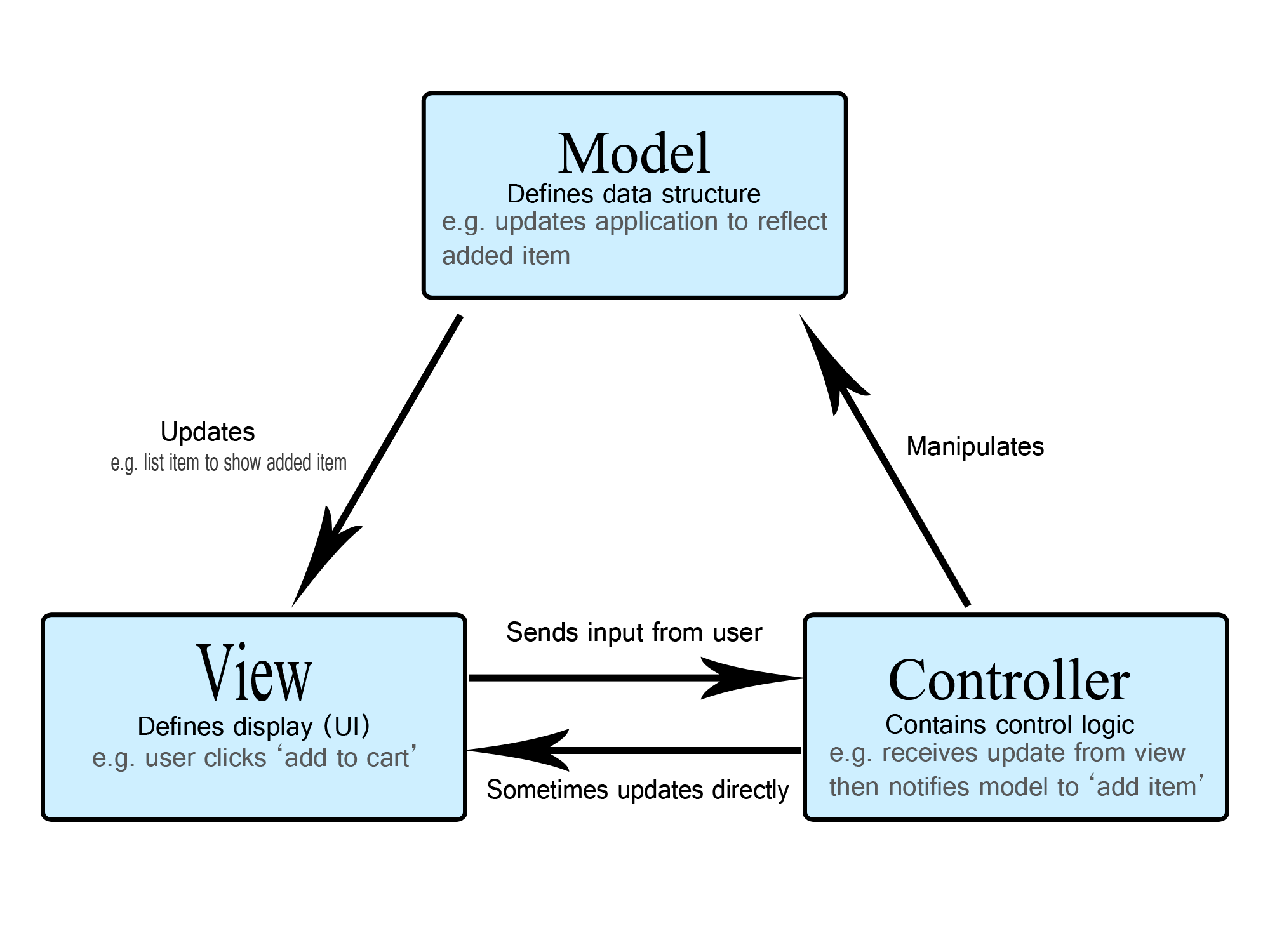
Consequently, it garnered widespread adoption within the industry because it made web application development more approachable and manageable. With a common understanding of the system, everyone involved had a better grasp of the process. This, in turn, led to an abundance of developers well-versed in the framework, making it easier and more cost-effective to find collaborators.
How about machine learning?
As I mentioned earlier, the arrival of all these ML and MLOps tools had minimal impact on the ability to productionize ML systems. Well, I dare think that it might have even contributed to decision fatigue, as being confronted by all these choices made the decision even more difficult to make.
Can we achieve the same outcome in machine learning as our developer cousins?
I believe so. The folks at Hopsworks developed the FTI architecture for machine learning systems. Instead of the usual single “end-to-end pipeline“, where the mental model has everything including the kitchen sink, they have recommended three separate pipelines - the Feature pipeline, the Training pipeline and the Inference pipeline.
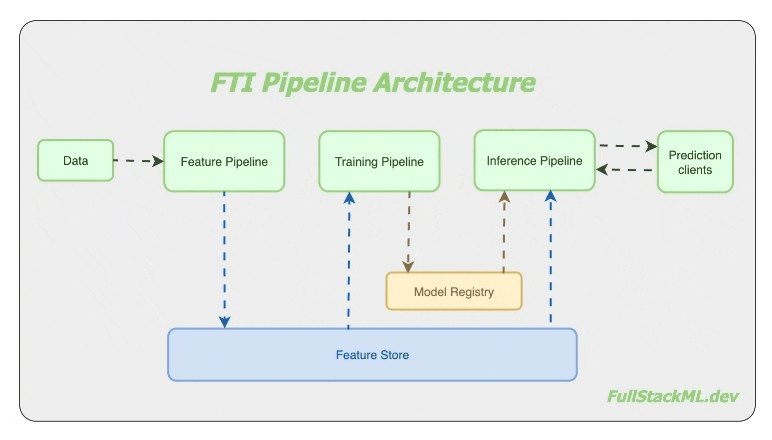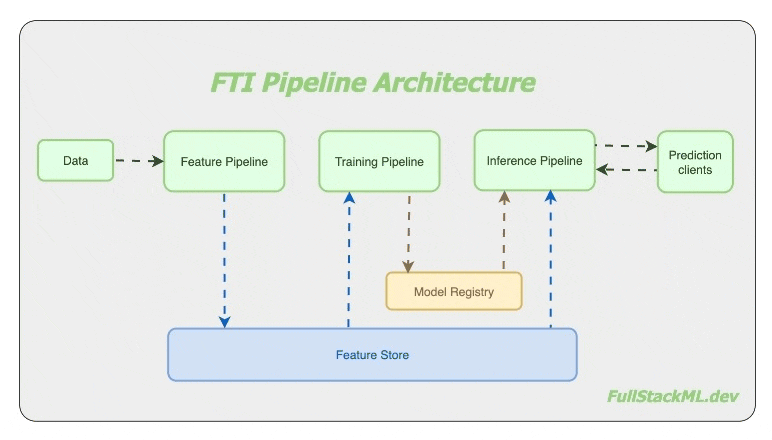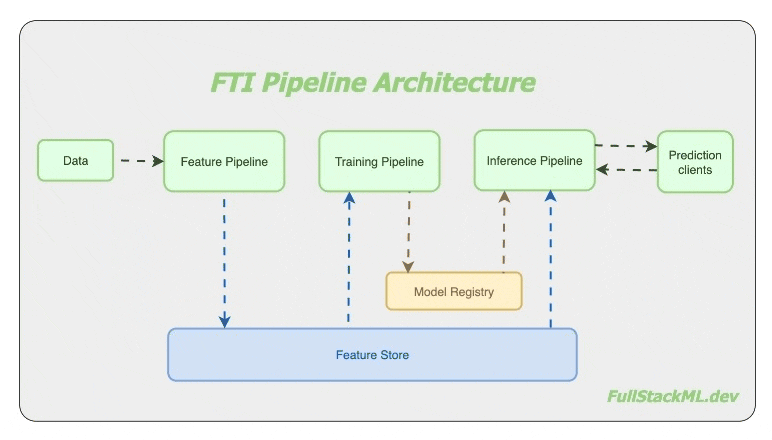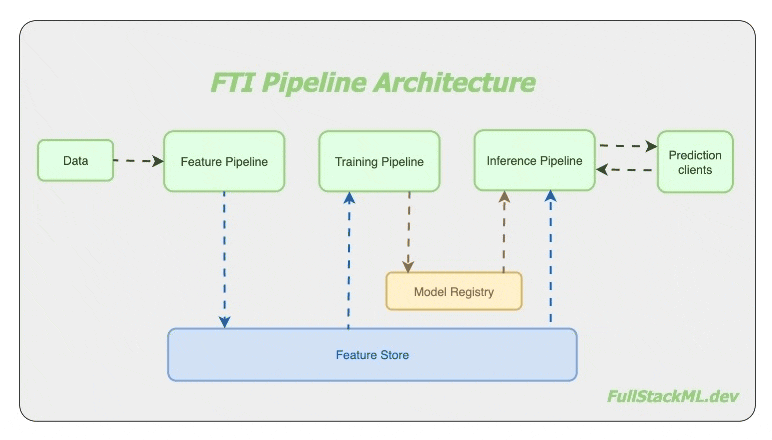
Although Uber Engineering pioneered using multiple pipelines to manage the scalability and complexity in machine learning systems, it looks like Hopsworks first came up with FTI architecture.
But how do multiple pipelines help?
At first glance, having multiple pipelines is counter-intuitive. Wouldn’t a single pipeline be simpler for our system, and easier to build and maintain? Well, yes it is a simpler system no doubt, however, typical ML systems deal with dynamic data, and we should have a system that supports that from the start.
A Feature pipeline regularly creates ‘features‘ from incoming data and saves it to a shared storage called a feature store. Typical systems have regular (if not streaming) data ingestion pipelines, so there is a need to operate the feature pipeline regularly, on-demand for streaming systems, or on a schedule for batch systems.
A Training pipeline reads training data from the feature store, trains the model and saves the trained model in a model registry. And because this pipeline is stand-alone, it can be 1) developed by someone else, and 2) invoked by a different schedule from the other pipelines.
And finally, the Inference pipeline is responsible for facilitating the prediction service. Call it on a schedule for batch inference systems, or if used for online inference, use any of the model serving infrastructure made available by many varied service providers.
Benefits of the FTI architecture
simple mental model of realistic machine learning systems
enables the development of maintainable ML systems in a relatively short period
reduced cognitive load when thinking about the whole ML system
modular pipelines provide clear boundaries and interfaces and promote collaboration between the multiple personas in an ML product team
open architecture - enables it to be cloud and tool-agnostic to avoid lock-in
Where do we go from here
In the next few editions, let’s develop a machine learning system from the ground up guided by this architecture. It will be fun, trust me.
Till then,
JO