
#5 - Let's build our image embedding model
Building an embedding model is not hard, and in this article we'll have a look at a couple of options

This article is part of a blog series about demistifying vector embedding models for use in image embeddings:
Part 1. So how do you build a vector embedding model? - Introduces vector embedding models and the intuition behind the technologies we can use to build one ourselves.
Part 2. Let's build our image embedding model - (this article) - Shows a couple of ways to build embedding models - first by using a pre-trained model, and next by fine-tuning a pre-trained model. We use PyTorch to build our feature extractor.
Part 3. Modelling with Metaflow and MLFlow - Here we are using Metaflow to build our model training workflow, where we introduce the concept of checkpointing, and MLFlow for experiment tracking.
Part 4. From Training to Deployment: A Simple Approach to Serving Embedding Models -Packaging your ML model in a Docker container opens it up to a multitude of model serving options.
Part 5. Putting Our Bird Embedding Model to Work: Introducing the Web Frontend -For our embedding model to prove useful to others, we have created a modern frontend to serve the similarity inference to our users.
Hi friends,
In the last article, we’ve been tasked by Bird Watch to build their bird species similarity search engine. We have a dataset of 525 bird species downloaded from Kaggle. I swear I got it originally from Kaggle, however when preparing this article, I couldn’t find it there anymore. I did find a copy in Hugging Face, so here it is.
A similarity search engine operates by extracting embedding vectors from images and calculating the distances between them. The magnitude of these distances indicates the degree of similarity between the images. To create an effective embedding model, it's essential to select a suitable image model and decide whether to use the pre-trained model as-is or to fine-tune it for your specific application. Using either will leverage the model’s feature extraction capabilities.
Let’s begin.
Option 1: Use a Pre-trained model
The breakthrough performance of AlexNet in 2012 opened the floodgates for deep learning in computer vision, leading to the discovery and development of numerous models over the years. These models not only improved accuracy but also became increasingly efficient. Notable examples include VGGNet (2014), ResNet (2015), MobileNet (2017), and Vision Transformers (ViT) (2020), all of which have pushed the boundaries of what's possible in image processing with deep learning.
For the purposes of this example, we will focus on a model from the ResNet family—specifically, ResNet-50. In my experience, ResNet-50 strikes an ideal balance between accuracy and computational efficiency, making it well-suited for this particular use case.
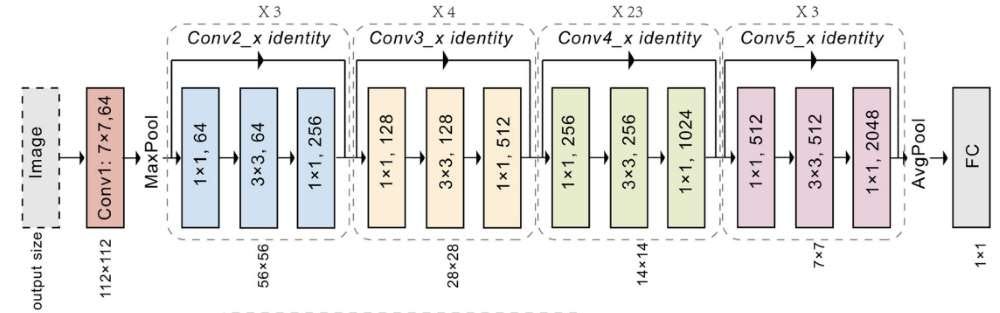
ResNet General Architectural Design
Follow with the Jupyter Notebook
Follow the scripts in a Jupyter notebook here.
Using a pre-trained model as an embedding model is the simplest and most efficient option. For instance, in our case, ResNet-50 has been pre-trained on the ImageNet dataset and includes a classifier head with 1000 classes. To create an embedding model, you only need to remove the final classification layer, transforming it into an embedding model that's ready to use for our bird species similarity search engine.
Similarity Search with pre-trained ResNet-50
In the following images, we used the pre-trained model as an embedding model. While it works to some extent, its performance isn't optimal. For example, it performed well for the Philippine Eagle and Parus Major but struggled with the Scarlet Tanager. Additionally, if you examine their similarity scores, you'll notice that the bird species are clustered too closely together. This is expected, as the ResNet-50 model was pre-trained on a 1,000-class dataset, including many categories beyond birds, which affects its ability to distinguish between different bird species in fine detail.



Issues with the pre-trained model
Using the ResNet-50 pre-trained embedding model presents a few key issues:
Similarity scores are too close together: The model fails to adequately distinguish between bird species in the dataset, with all similarity scores falling within the 0.8xx range. This lack of variation suggests the model isn't capturing enough nuanced differences between species.
Sensitivity to image variations: The model is highly sensitive to changes in image orientation, rotation and lighting. For instance, showing it different variations of the same bird species—such as flipped or rotated images or different lighting conditions—leads to inconsistent and poor results, indicating a lack of robustness in handling such variations.
Option 2: Fine-tune a pre-trained model
Another approach is to fine-tune the ResNet-50 model. This means starting with the pre-trained ResNet-50, leveraging the weights it learned during its initial training. Fine-tuning offers a significant advantage over training from scratch, which would require hundreds of hours and millions of images—resources we don’t have, nor need. Instead, fine-tuning allows us to quickly adapt the model for our specific use case, essentially taking a shortcut to build an effective embedding model.
Fine-tuning an embedding model follows a process similar to training a classifier. In our case, since we are working with a smaller dataset of 50 classes, we start the process as if we are training a 50-class classifier. After training, we simply remove the final classifier layer, converting the model into an embedding model ready to handle our similarity search use case.
Follow with the Jupyter Notebook
Here is the Jupyter Notebook for fine-tuning a pre-trained ResNet-50 model.
In the images below, we used the same set as in the pre-trained experiment, but this time we generated embeddings using the fine-tuned ResNet-50 model. The results show a drastic improvement, both in accuracy and the returned similarity scores.
Similarity Search with fine-tuned ResNet-50
All unknown birds were matched correctly as the top result. Moreover, the range of similarity scores is much more promising—where the top match has a similarity score close to 1, and the remaining results have scores closer to zero. This demonstrates that the fine-tuned model captures bird species embeddings with far greater precision.
For example, the unknown birds—Philippine Eagle, Scarlet Tanager, and Parus Major—all returned the correct match as the top result! It's clear we've built a highly effective bird species embedding model, and impressively, the model is just under 100MB in size.



Conclusion
While the Bird Watch project is hypothetical, the techniques we've explored in using embedding models—both pre-trained and fine-tuned—are very much applicable in the real world. The ResNet-50 model we utilized was introduced by Microsoft in 2015, so it may not be considered cutting-edge technology. However, it's important to not underestimate the power of these machine learning models. With its ideal balance of accuracy and latency, these models continue to see widespread application in the industry today.
Although we are applying this technology in a conceptual project like our bird species similarity search application, the same methods continue to be used in critical areas such as automated visual inspection and quality control in manufacturing, as well as in medical imaging for diagnosis and cancer detection.
Till then,
JO